本地服务器部署deepseek,打造自己专属知识库
第一步:安装Ollama
打开官方网址:https://ollama.com/download/linux
下载Ollama linux版本
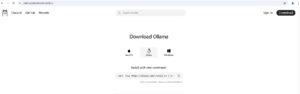
根据提示复制命令到centos执行:
curl -fsSL https://ollama.com/install.sh | sh

提示没有GPU,不用管,直接进入下一步,修改配置:
vi /etc/systemd/system/ollama.service
增加下面两行:
Environment=”OLLAMA_HOST=0.0.0.0″
Environment=”OLLAMA_ORIGINS=*”
然后载入配置:
systemctl daemon-reload
重启ollama
systemctl restart ollama
查看ollama启动状态:
[root@localhost ~]# systemctl status ollama
● ollama.service – Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: disabled)
Active: active (running) since 四 2025-02-06 13:17:38 CST; 5min ago
Main PID: 64206 (ollama)
CGroup: /system.slice/ollama.service
└─64206 /usr/local/bin/ollama serve
查看端口状态:
ss -anlp|grep 11434
开启防火墙:
firewall-cmd –zone=public –add-port=11434/tcp –permanent
重启防火墙后外网访问:
firewall-cmd –reload

第二步:部署Deepseek R1模型
还是在ollama官网上,https://ollama.com/library/deepseek-r1:7b 点击Models,选择deepseek-r1,不同版本对应的体积大小不同,体积越大模型越精细化,只需要复制命令即可,我这里选择7b。
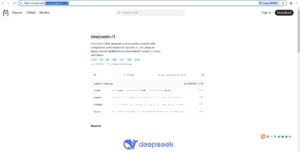
复制命令执行:
ollama run deepseek-r1:7b
如果出现错误:
pulling manifest
Error: pull model manifest: Get “https://registry.ollama.ai/v2/library/deepseek-r1/manifests/14b”: net/http: TLS handshake timeout
则按照下面步骤执行重启ollama模型:
用ollama拉取新的模型时 出错了
开始以为清理一下缓存就可以了,后来发现不行。
然后重启了一下ollama服务就解决了。
停止ollama服务:
sudo systemctl stop ollama
运行一下之前安装好的模型检查是否已停止:
ollama run llama3
启动ollama服务:
sudo systemctl start ollama
重启服务后重新拉取模型可以正常拉取了。
![]()
安装成功:
![]()
第三步:配置可视化界面
安装docker
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install docker-ce-20.10.9-3.el7 docker-ce-cli-20.10.9-3.el7 containerd.io
systemctl start docker
systemctl status docker
docker –version
docker info
安装可视化页面:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.234.108:11434 -v open-webui:/app/backend/data –name open-webui –restart always ghcr.io/open-webui/open-webui:main

开放端口:
firewall-cmd –zone=public –add-port=3000/tcp –permanent
firewall-cmd –reload
安装成功后访问控制台:
http://192.168.234.108:3000
![]()